Data Science
What Is Perception in Neural Networks?
Perceptron's are the building blocks of neural networks. A single layer perceptron is called neural network and a multi-layer perceptron is called Neural Networks. Perceptron is a linear classifier (binary). It is typically used for supervised learning.
Neural networks, also known as artificial neural networks (ANNs) or simulated neural networks (SNNs), are a subset of machine learning that provide the foundation of deep learning techniques. Neural networks are computational algorithms or models that understand the data and process information. Their name and structure are inspired by the human brain, mimicking the way that biological neurons signal to one another.

This is an excellent illustration of the human brain. Our brains were empty at birth, but when we encountered the real world, we learned about things by seeing them or hearing about them. In a same way our system learns from the data and past experience to identify the patterns and makes predictions.
The role of neurons in the brain is played by the perceptron in a neural network. A perceptron can learn to detect input data computations in business intelligence. Perceptron algorithms help in the linear separation of classes and patterns based on the numerical or visual input data.

Components of a Perceptron
A perceptron consists of
- Input values
- Weights and Bias
- Net sum (weighted sum)
- Activation Function- It explains the non-linearity in the perceptron model.

Why do we Need Weight and Bias?
Weight and bias are two essential components of the perceptron model. These are learnable parameters, and as the network is trained, both parameters are adjusted to reach the desired values and output.
Weights are used to determine how important each feature is in forecasting output value. Features with near-zero values are deemed to have less weight or relevance. These are less important in the prediction process than features with values greater than zero, known as weights with a higher value. If a feature’s weight is positive, it has a direct link with the target value; if it is negative, it has an inverse relationship with the target value.
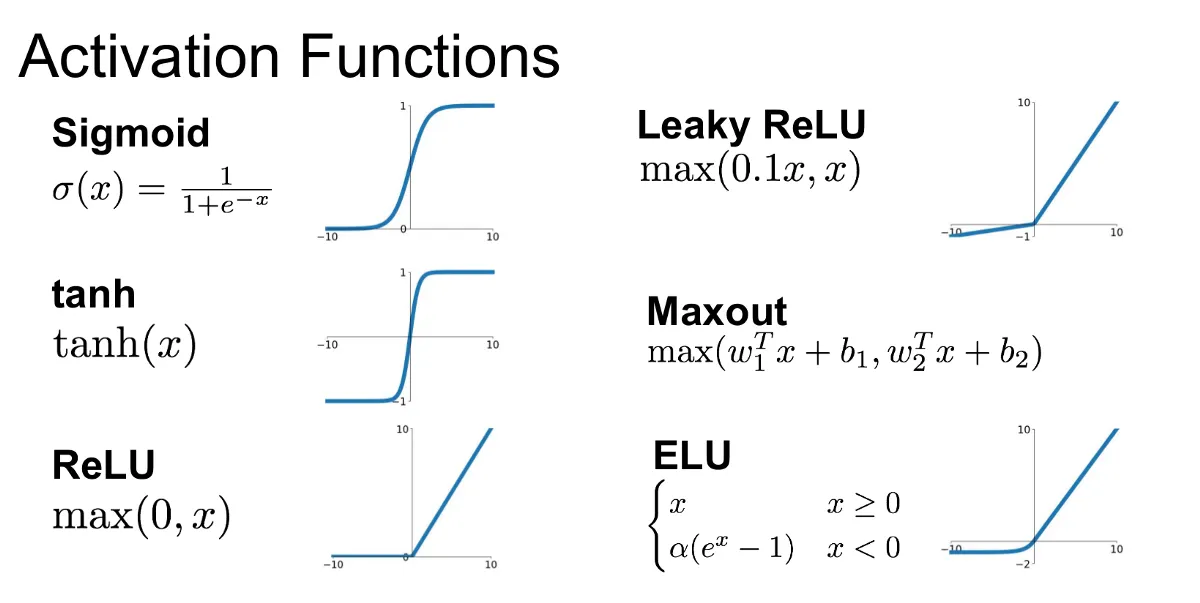
Why do we need Activation Function?
The activation function is an important part of an artificial neural network. They basically decide whether a neuron should be activated or not
How does Perceptron work?
Tutorial 2- How does Neural Network Work — YouTube
- All the inputs x1,x2,x3…xn are given to the input layer and weights are assigned once an input layer has been defined.
- All inputs are then multiplied by respective weights and added together.

3. Apply that weighted sum to the correct Activation Function. The output is processed by an activation function, which decides the output.
- For Binary classification we the Sigmoid Activation function
- For multiclassification we generally use SoftMax Activation function at the output layer and variation of ReLU Activation function at Hidden layers.

4. Use cost function to get the output, when the perceptron’s input values are similar to those desired for its anticipated output, we can claim that it performed satisfactorily.

5. If there is a difference between what was expected and what was obtained, the weights must be adjusted to restrict the extent to which these errors effect future forecasts based on unchanged parameters.
Perceptron Model
The perceptron model was deployed for machine-driven picture recognition for the first time in 1957 at Cornell Aeronautical Laboratory in the United States. It was claimed to be the most notable AI-based innovation because it was the first artificial neural network.
The perceptron algorithm, on the other hand, has certain technological limitations. Because it was single-layered, the perceptron model could only be applied to linearly separable classes. The invention of multi-layered perceptron algorithms later resolved the problem. Here is a more in-depth look at the various sorts of perceptron models:
Single Layer Perceptron Model
SLP is the most basic type of artificial neural network, and it can only classify situations that are linearly separable with a binary target (1, 0). Activation functions are neural network decision-making components. They calculate net output of a neural node.

A single layer perceptron (SLP) is a feed-forward network (To generate some output, the input data should only be fed forward. The input should not flow backwards during output generation; otherwise, a cycle would occur and the output would never be formed. This type of network arrangement is known as a feed-forward network. Forward propagation is aided by the feed-forward network.) based on a threshold transfer function.
Multilayer Perceptron Model
The multi-layer perceptron model, often known as the Backpropagation algorithm, works in two stages: Forward Stage: In the forward stage, activation functions begin on the input layer and end on the output layer. Backward Stage: In the backward stage, weight and bias values are adjusted to meet the needs of the model.

Forward propagation
As the name suggests, the input data is fed in the forward direction through the network. Forward propagation is the way data moves from left (input layer) to right (output layer) in the neural network. Each hidden layer accepts input data, processes it according to the activation function, and then sends it on to the next layer.

Backward propagation
The process of moving from the right to left that is backward from the Output to the Input layer is called the Backward Propagation. Backpropagation in neural networks is an abbreviation for “backward error propagation.” The core of neural network training is backpropagation. It is a common technique for training artificial neural networks. It is a preferable method of fine-tuning neural network weights based on the error rate achieved in the previous epoch (i.e., iteration (Forword propagation + backward propagation). By fine-tuning (adjusting or correcting) the weights, we can minimize error rates and make the model more Accurate.
Limitations of the Perceptron Model
A perceptron model has the following limitations:
- The perceptron generates only a binary number (0 or 1) as an output due to the hard limit transfer function.
- A single layer perceptron can only learn linearly separable problems. Boolean AND function is linearly separable, whereas Boolean X OR function (and the parity problem in general) is not. Hence non-linear input vectors cannot be classified properly.
Any comments or if you have any questions, write them in the comment.
Clap it! Share it! Follow Me!
Happy to be helpful. …..
References
